#Queries Database Online Help
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
So you've wrote a book, what's next?
So I recently started uni and naturally immediately joined my universities writing and book societies, last week I was sat editing my book when a couple of people approached me. Apparently through some light instagram stalking they had found out I published books and was wondering how on earth do you even do it.
Upon being on tumblr this week it turns out that this is a question that a lot of people are interested in, this being probably my most requested post ever?
ANYWAY. You've wrote a book, either you're two drafts in or fifty drafts in it doesn't entirely matter. I am going to give you the bad news that the work has only just begun.
The first choice you really need to make is whether or not you want to pursue traditional publishing or self/indie publishing. I believe the common misconception of the difference between the two is that one is 'Easier' than the other. Both are hard, just in different ways.
Traditional publishing is hard to break into, you need to convince enough of people that your book is worth selling which can be incredibly difficult and results in a lot of heartbreaking emails. However once you have that publishing deal you have those people in your corner to help with editing, cover design, and distribution among other things.
Self publishing, much like the name suggests, means that you have to do everything yourself, edit (or source an editor), design (or source a designer), marketing, the works. However the plus side of self publishing which I like is that you have a lot more creative control and freedom.
Now to be fully transparent, I am an indie author, naturally I am going to know a lot more about a process I have actually gone through rather than one I havent. However I do believe I can provide at least a rough guideline of the process so that people can get an idea of what going into it.
So starting with traditional publishing, assuming that you have a full draft that you've at least done some self editing on, your first step is finding an agent. You'll need a couple of things for this. First is make a document of the first 30 pages of your manuscript (a 'sample' if you will), and a query letter which is almost like a cover letter for your book, this is what potential agents will look at to judge whether they want to represent your manuscript.
I dont think I need to say it but your query letter is VITAL, please take time with it, some agents may not even look at your sample if your query letter is bad.
Now, searching for agents is relatively easy, there are a lot of databases online that will give you a list of agents and whether or not they are accepting submissions. Most agents will also have a kind of 'wishlist' of manuscripts they're looking to represent (e.g. sci-fi, philosophy, high fantasy), look for agents with a wishlist that includes your kind of book.
Once you have an agent they will be able to go to different publishing houses with your manuscript, hopefully leading to a book deal at some point. From there the publishers will help with editing, design, and distribution.
With self publishing the process is a bit more complicated. First is the editing process. Either you can edit your own manuscript if you feel up to it or you can source an editor. There are three different editors you can hire: Developmental editor, Line editor, and Proof reader. Almost every editor charges per word of your manuscript.
I would also recommend looking for Beta readers, these are readers who will read through an early copy of your manuscript for feedback (These are NOT editors, more reviewers). There are also ARC readers who you send an early copy to about 2-3 months before release to build interest in your book.
When it comes to the actual publishing itself, there are two main publishing platforms: kdp and ingram spark. Both of these are three besides the fact that you will need to buy an ISPN for your book to use ingram spark.
I think i'll leave it there because this is LONG, but i may turn this into a series, what do y'all want to know about?
#writeblr#writers of tumblr#writing#bookish#booklr#creative writing#fantasy books#ya fantasy books#book blog#ya books#writers block#fantasy writer#am writing#female writers#fiction writing#how to write#story writing#teen writer#tumblr writers#tumblr writing community#writblr#writer community#writer problems#writer stuff#writerblr#writers#writers community#writers corner#writers on tumblr#writers life
72 notes
·
View notes
Text
Experts fear Trump’s 'legitimately frightening' new order to turn US military into police
Trump's new order, which is entitled "Strengthening and Unleashing America's Law Enforcement to Pursue Criminals and Protect Innocent Citizens," makes various declarations about the administration's commitment to supporting law enforcement professionals in the opening paragraphs. However, one section further down specifically mentions the U.S. military and the administration's intent to have enlisted service members participate in civilian law enforcement actions.
https://www.alternet.org/trump-order-military-police/
Trump Has Ordered Safeguards Stripped From Procurement As Pentagon Prepares To Spend $1 Trillion
https://talkingpointsmemo.com/news/trump-procurement-executive-orders-defense
DOGE employees gain accounts on classified networks holding nuclear secrets
https://www.npr.org/2025/04/28/nx-s1-5378684/doge-energy-department-nuclear-secrets-access
American Panopticon The Trump administration is pooling data on Americans. Experts fear what comes next.
In March, President Trump issued an executive order aiming to eliminate the data silos that keep everything separate. Historically, much of the data collected by the government had been heavily compartmentalized and secured; even for those legally authorized to see sensitive data, requesting access for use by another government agency is typically a painful process that requires justifying what you need, why you need it, and proving that it is used for those purposes only. Not so under Trump.
. . .
A worst-case scenario is easy to imagine. Some of this information could be useful simply for blackmail—medical diagnoses and notes, federal taxes paid, cancellation of debt. In a kleptocracy, such data could be used against members of Congress and governors, or anyone disfavored by the state. Think of it as a domesticated, systemetized version of kompromat—like opposition research on steroids: Hey, Wisconsin is considering legislation that would be harmful to us. There are four legislators on the fence. Query the database; tell me what we’ve got on them.
Say you want to arrest or detain somebody—activists, journalists, anyone seen as a political enemy—even if just to intimidate them. An endless data set is an excellent way to find some retroactive justification. Meyer told us that the CFPB keeps detailed data on consumer complaints—which could also double as a fantastic list of the citizens already successfully targeted for scams, or people whose financial problems could help bad actors compromise them or recruit them for dirty work.
Similarly, FTC, SEC, or CFPB data, which include subpoenaed trade secrets gathered during long investigations, could offer the ability for motivated actors to conduct insider trading at previously unthinkable scale. The world’s richest man may now have access to that information.
An authoritarian, surveillance-control state could be supercharged by mating exfiltrated, cleaned, and correlated government information with data from private stores, corporations who share their own data willingly or by force, data brokers, or other sources.
What kind of actions could the government perform if it could combine, say, license plates seen at specific locations, airline passenger records, purchase histories from supermarket or drug-store loyalty cards, health-care patient records, DNS-lookup histories showing a person’s online activities, and tax-return data?
It could, for example, target for harassment people who deducted charitable contributions to the Palestine Children’s Relief Fund, drove or parked near mosques, and bought Halal-certified shampoos. It could intimidate citizens who reported income from Trump-antagonistic competitors or visited queer pornography websites.
It could identify people who have traveled to Ukraine and also rely on prescription insulin, and then lean on insurance companies to deny their claims. These examples are all speculative and hypothetical, but they help demonstrate why Americans should care deeply about how the government intends to manage their private data.
https://www.theatlantic.com/technology/archive/2025/04/american-panopticon/682616/
Trump Administration to Judges: ‘We Will Find You’ The attorney general’s message to the judiciary is clear.
https://www.theatlantic.com/politics/archive/2025/04/trump-administration-initimidates-judges/682620/
ETA: Its latest effort to bring the press to heel came on April 25, when news leaked of the Justice Department’s intention to aggressively pursue journalists who receive leaked information from confidential government sources.
The Guardian reports that Bondi “has revoked a Biden administration-era policy that restricted subpoenas of reporters’ phone records in criminal investigations
https://www.salon.com/2025/04/29/looking-to-trumps-next-100-days-doj-tees-up-process-for-jailing-journalists/
4 notes
·
View notes
Text
Saw a post going around that included commentary on the stagnation of AI, but I don't feel like jumping into a major post and have too many thoughts for tags, so I'm dumping them here.
Co-workers do not believe me when I voice my AI concerns using the argument of stagnation. They are certain this will never happen and people will just get better at querying the system.
However...
Even if AI had access to exponentially massive troves of data, stagnation will still happen. The data that is used is going to be put back into the pool, making it slightly more common than other data points. AI will therefore be more likely to pick it up because it is programmed to spit out the most likely answer. That answer will then be put back into the pool, making it slightly more common...
Feel me?
Co-workers will try to tell me that people will still be putting new things out to mitigate this, but they will not. They will all be using AI, which is feeding them the same information, which they will use and put back into the pool. There will be no more creativity because creatives are expensive and will be replaced with AI, which will draw out the same information and put it back into the pool. There will be no new creatives because none of them will learn how to do anything without AI, which will feed them all the same information, which they will put back into the pool.
Add to the problem that AI is an extremely broad term, so any argument against it brings the "but what about?" crowd out of the walls.
So to be clear: limited or directed AI is not the same problem as generative AI.
An app that uses AI to check information against set parameters (e.g. spellcheck, grammar check, style manual citation check...) can be legitimately useful.
AI that can speak back text in multiple languages or generate accurate subtitles because its information is curated can assist in accessibility.
AI that has access to set database of medical information can help sort that information and make comparisons quickly and efficiently, (as long as it's not relied upon to make definite diagnoses).
But AI that has to reach down into the collective brain vomit of human kind?
Unreliable at best. Straight-up bigoted at worst.
Not sure where I'm going with this other than to say don't rely on AI. Especially not generative AI. Be wary of anything you find online unless you can verify the source. And then, ideally, make sure you have at least three (non-AI) sources that agree.
Misinformation is like mosquitoes. You're gonna get bit by it once in a while. But the damage can be mitigated with precautions and aftercare.
Be careful out there.
2 notes
·
View notes
Text
Why Your Business Might Be Falling Behind Without AI App Development or Modern Web Solutions
In today’s fast-paced digital landscape, staying competitive isn’t just about having an online presence — it’s about having the right kind of presence. Many businesses invest in a website or a mobile app and stop there. But without integrating AI app development services and scalable, intelligent business web development services, they risk falling behind.
So, what’s causing this gap, and how can businesses close it?
The Real Challenge: Businesses Aren’t Evolving with User Expectations
User behavior has dramatically changed over the last few years. Customers expect fast, personalized, and intuitive digital experiences. They want websites that respond to their needs, apps that understand their preferences, and services that anticipate their next move. Businesses that are still running on legacy systems or using outdated platforms simply can’t meet these rising expectations.
Let’s say a user visits your website to schedule a consultation or find a product. If your system takes too long to load or offers no AI-driven suggestions, you’ve already lost them — probably to a competitor that’s already using AI app development services to enhance user interaction.
The Role of AI in Transforming Business Applications
Artificial Intelligence is no longer limited to tech giants. From personalized product recommendations to intelligent customer service chatbots, AI app development services are helping businesses of all sizes create smart, responsive applications.
Some examples of what AI can do in a business app include:
Automating repetitive customer queries
Offering personalized product or content recommendations
Identifying user behavior patterns and adapting accordingly
Reducing human errors in backend processes
By integrating AI into mobile or web apps, companies can streamline operations, improve customer satisfaction, and gain deeper insights into user behavior. And as these capabilities become the new norm, not having them means you’re offering a subpar experience by default.
The Foundation: Scalable Business Web Development Services
While AI powers intelligence, you still need a strong digital infrastructure to support it. This is where business web development services come in.
A well-developed business website isn’t just about looking good. It should be:
Responsive: accessible and easy to navigate on all devices
Scalable: ready to handle increased traffic or new features without a full rebuild
Secure: with updated protocols to protect user data
Fast: with optimized loading times for better user retention
These elements don’t just “happen.” They require planning, strategy, and expertise. Modern business web development services help create these experiences, combining functionality with user-centric design.
Let’s not forget the importance of backend systems either — inventory management, CRM integration, user databases, and more all need to run smoothly in the background to support the front-end user experience.
Why the Gap Still Exists
Despite the availability of these technologies, many businesses hesitate to adopt them. Common reasons include:
Fear of high development costs
Uncertainty about where to start
Lack of technical knowledge or internal teams
Belief that AI and advanced web systems are “only for big companies”
But these concerns often stem from a lack of awareness. Platforms like Fenebris India are already offering tailored AI app development services and business web development services that cater specifically to startups, SMBs, and growing enterprises — without the hefty price tag or complex jargon.
The key is to think in terms of long-term growth rather than short-term fixes. A custom-built AI-enabled app or a modern, scalable web system may require some upfront investment, but it significantly reduces future inefficiencies and technical debt.
How to Start Evolving Your Digital Strategy
If you're not sure where to begin, consider these initial steps:
Audit your current digital presence: What features are outdated or missing?
Identify customer pain points: Are users dropping off before completing actions? Are your support channels responsive enough?
Define your goals: Do you want more engagement, smoother operations, better insights?
Consult experts: Work with a team that understands both AI and business development needs.
You don’t have to overhaul everything at once. Even small changes — like adding a chatbot, integrating AI for personalized content, or improving page speed — can have a significant impact.
Final Thoughts
The future belongs to businesses that adapt quickly and intelligently. Whether it’s by embracing AI app development services to build smarter tools or by investing in professional business web development services to offer faster, more reliable experiences — staying competitive means staying current.
Digital transformation isn’t about trends. It’s about survival, growth, and being there for your customers in the ways they now expect.
#web development company in noida#web development services agency#best artificial intelligence development company#ai app development services
2 notes
·
View notes
Text
Data warehousing solution
Unlocking the Power of Data Warehousing: A Key to Smarter Decision-Making
In today's data-driven world, businesses need to make smarter, faster, and more informed decisions. But how can companies achieve this? One powerful tool that plays a crucial role in managing vast amounts of data is data warehousing. In this blog, we’ll explore what data warehousing is, its benefits, and how it can help organizations make better business decisions.
What is Data Warehousing?
At its core, data warehousing refers to the process of collecting, storing, and managing large volumes of data from different sources in a central repository. The data warehouse serves as a consolidated platform where all organizational data—whether from internal systems, third-party applications, or external sources—can be stored, processed, and analyzed.
A data warehouse is designed to support query and analysis operations, making it easier to generate business intelligence (BI) reports, perform complex data analysis, and derive insights for better decision-making. Data warehouses are typically used for historical data analysis, as they store data from multiple time periods to identify trends, patterns, and changes over time.
Key Components of a Data Warehouse
To understand the full functionality of a data warehouse, it's helpful to know its primary components:
Data Sources: These are the various systems and platforms where data is generated, such as transactional databases, CRM systems, or external data feeds.
ETL (Extract, Transform, Load): This is the process by which data is extracted from different sources, transformed into a consistent format, and loaded into the warehouse.
Data Warehouse Storage: The central repository where cleaned, structured data is stored. This can be in the form of a relational database or a cloud-based storage system, depending on the organization’s needs.
OLAP (Online Analytical Processing): This allows for complex querying and analysis, enabling users to create multidimensional data models, perform ad-hoc queries, and generate reports.
BI Tools and Dashboards: These tools provide the interfaces that enable users to interact with the data warehouse, such as through reports, dashboards, and data visualizations.
Benefits of Data Warehousing
Improved Decision-Making: With data stored in a single, organized location, businesses can make decisions based on accurate, up-to-date, and complete information. Real-time analytics and reporting capabilities ensure that business leaders can take swift action.
Consolidation of Data: Instead of sifting through multiple databases or systems, employees can access all relevant data from one location. This eliminates redundancy and reduces the complexity of managing data from various departments or sources.
Historical Analysis: Data warehouses typically store historical data, making it possible to analyze long-term trends and patterns. This helps businesses understand customer behavior, market fluctuations, and performance over time.
Better Reporting: By using BI tools integrated with the data warehouse, businesses can generate accurate reports on key metrics. This is crucial for monitoring performance, tracking KPIs (Key Performance Indicators), and improving strategic planning.
Scalability: As businesses grow, so does the volume of data they collect. Data warehouses are designed to scale easily, handling increasing data loads without compromising performance.
Enhanced Data Quality: Through the ETL process, data is cleaned, transformed, and standardized. This means the data stored in the warehouse is of high quality—consistent, accurate, and free of errors.
Types of Data Warehouses
There are different types of data warehouses, depending on how they are set up and utilized:
Enterprise Data Warehouse (EDW): An EDW is a central data repository for an entire organization, allowing access to data from all departments or business units.
Operational Data Store (ODS): This is a type of data warehouse that is used for storing real-time transactional data for short-term reporting. An ODS typically holds data that is updated frequently.
Data Mart: A data mart is a subset of a data warehouse focused on a specific department, business unit, or subject. For example, a marketing data mart might contain data relevant to marketing operations.
Cloud Data Warehouse: With the rise of cloud computing, cloud-based data warehouses like Google BigQuery, Amazon Redshift, and Snowflake have become increasingly popular. These platforms allow businesses to scale their data infrastructure without investing in physical hardware.
How Data Warehousing Drives Business Intelligence
The purpose of a data warehouse is not just to store data, but to enable businesses to extract valuable insights. By organizing and analyzing data, businesses can uncover trends, customer preferences, and operational inefficiencies. Some of the ways in which data warehousing supports business intelligence include:
Customer Segmentation: Companies can analyze data to segment customers based on behavior, demographics, or purchasing patterns, leading to better-targeted marketing efforts.
Predictive Analytics: By analyzing historical data, businesses can forecast trends and predict future outcomes, such as sales, inventory needs, and staffing levels.
Improved Operational Efficiency: With data-driven insights, businesses can streamline processes, optimize supply chains, and reduce costs. For example, identifying inventory shortages or surplus can help optimize stock levels.
Challenges in Data Warehousing
While the benefits of data warehousing are clear, there are some challenges to consider:
Complexity of Implementation: Setting up a data warehouse can be a complex and time-consuming process, requiring expertise in database management, ETL processes, and BI tools.
Data Integration: Integrating data from various sources with differing formats can be challenging, especially when dealing with legacy systems or unstructured data.
Cost: Building and maintaining a data warehouse can be expensive, particularly when managing large volumes of data. However, the investment is often worth it in terms of the business value generated.
Security: With the consolidation of sensitive data in one place, data security becomes critical. Organizations need robust security measures to prevent unauthorized access and ensure compliance with data protection regulations.
The Future of Data Warehousing
The world of data warehousing is constantly evolving. With advancements in cloud technology, machine learning, and artificial intelligence, businesses are now able to handle larger datasets, perform more sophisticated analyses, and automate key processes.
As companies increasingly embrace the concept of a "data-driven culture," the need for powerful data warehousing solutions will continue to grow. The integration of AI-driven analytics, real-time data processing, and more intuitive BI tools will only further enhance the value of data warehouses in the years to come.
Conclusion
In today’s fast-paced, data-centric world, having access to accurate, high-quality data is crucial for making informed business decisions. A robust data warehousing solution enables businesses to consolidate, analyze, and extract valuable insights from their data, driving smarter decision-making across all departments. While building a data warehouse comes with challenges, the benefits—improved efficiency, better decision-making, and enhanced business intelligence—make it an essential tool for modern organizations.
You said:
blog for Data warehousing
ChatGPT said:
Title: Data Warehousing: The Backbone of Data-Driven Decision Making
In today’s fast-paced business environment, the ability to make data-driven decisions quickly is paramount. However, to leverage data effectively, companies need more than just raw data. They need a centralized, structured system that allows them to store, manage, and analyze data seamlessly. This is where data warehousing comes into play.
Data warehousing has become the cornerstone of modern business intelligence (BI) systems, enabling organizations to unlock valuable insights from vast amounts of data. In this blog, we’ll explore what data warehousing is, why it’s important, and how it drives smarter decision-making.
What is Data Warehousing?
At its core, data warehousing refers to the process of collecting and storing data from various sources into a centralized system where it can be easily accessed and analyzed. Unlike traditional databases, which are optimized for transactional operations (i.e., data entry, updating), data warehouses are designed specifically for complex queries, reporting, and data analysis.
A data warehouse consolidates data from various sources—such as customer information systems, financial systems, and even external data feeds—into a single repository. The data is then structured and organized in a way that supports business intelligence (BI) tools, enabling organizations to generate reports, create dashboards, and gain actionable insights.
Key Components of a Data Warehouse
Data Sources: These are the different systems or applications that generate data. Examples include CRM systems, ERP systems, external APIs, and transactional databases.
ETL (Extract, Transform, Load): This is the process by which data is pulled from different sources (Extract), cleaned and converted into a usable format (Transform), and finally loaded into the data warehouse (Load).
Data Warehouse Storage: The actual repository where structured and organized data is stored. This could be in traditional relational databases or modern cloud-based storage platforms.
OLAP (Online Analytical Processing): OLAP tools enable users to run complex analytical queries on the data warehouse, creating reports, performing multidimensional analysis, and identifying trends.
Business Intelligence Tools: These tools are used to interact with the data warehouse, generate reports, visualize data, and help businesses make data-driven decisions.
Benefits of Data Warehousing
Improved Decision Making: By consolidating data into a single repository, decision-makers can access accurate, up-to-date information whenever they need it. This leads to more informed, faster decisions based on reliable data.
Data Consolidation: Instead of pulling data from multiple systems and trying to make sense of it, a data warehouse consolidates data from various sources into one place, eliminating the complexity of handling scattered information.
Historical Analysis: Data warehouses are typically designed to store large amounts of historical data. This allows businesses to analyze trends over time, providing valuable insights into long-term performance and market changes.
Increased Efficiency: With a data warehouse in place, organizations can automate their reporting and analytics processes. This means less time spent manually gathering data and more time focusing on analyzing it for actionable insights.
Better Reporting and Insights: By using data from a single, trusted source, businesses can produce consistent, accurate reports that reflect the true state of affairs. BI tools can transform raw data into meaningful visualizations, making it easier to understand complex trends.
Types of Data Warehouses
Enterprise Data Warehouse (EDW): This is a centralized data warehouse that consolidates data across the entire organization. It’s used for comprehensive, organization-wide analysis and reporting.
Data Mart: A data mart is a subset of a data warehouse that focuses on specific business functions or departments. For example, a marketing data mart might contain only marketing-related data, making it easier for the marketing team to access relevant insights.
Operational Data Store (ODS): An ODS is a database that stores real-time data and is designed to support day-to-day operations. While a data warehouse is optimized for historical analysis, an ODS is used for operational reporting.
Cloud Data Warehouse: With the rise of cloud computing, cloud-based data warehouses like Amazon Redshift, Google BigQuery, and Snowflake have become popular. These solutions offer scalable, cost-effective, and flexible alternatives to traditional on-premises data warehouses.
How Data Warehousing Supports Business Intelligence
A data warehouse acts as the foundation for business intelligence (BI) systems. BI tools, such as Tableau, Power BI, and QlikView, connect directly to the data warehouse, enabling users to query the data and generate insightful reports and visualizations.
For example, an e-commerce company can use its data warehouse to analyze customer behavior, sales trends, and inventory performance. The insights gathered from this analysis can inform marketing campaigns, pricing strategies, and inventory management decisions.
Here are some ways data warehousing drives BI and decision-making:
Customer Insights: By analyzing customer purchase patterns, organizations can better segment their audience and personalize marketing efforts.
Trend Analysis: Historical data allows companies to identify emerging trends, such as seasonal changes in demand or shifts in customer preferences.
Predictive Analytics: By leveraging machine learning models and historical data stored in the data warehouse, companies can forecast future trends, such as sales performance, product demand, and market behavior.
Operational Efficiency: A data warehouse can help identify inefficiencies in business operations, such as bottlenecks in supply chains or underperforming products.

2 notes
·
View notes
Text
My Experience with Database Homework Help from DatabaseHomeworkHelp.com
As a student majoring in computer science, managing the workload can be daunting. One of the most challenging aspects of my coursework has been database management. Understanding the intricacies of SQL, ER diagrams, normalization, and other database concepts often left me overwhelmed. That was until I discovered Database Homework Help from DatabaseHomeworkHelp.com. This service has been a lifesaver, providing me with the support and guidance I needed to excel in my studies.
The Initial Struggle
When I first started my database course, I underestimated the complexity of the subject. I thought it would be as straightforward as other programming courses I had taken. However, as the semester progressed, I found myself struggling with assignments and projects. My grades were slipping, and my confidence was waning. I knew I needed help, but I wasn't sure where to turn.
I tried getting assistance from my professors during office hours, but with so many students needing help, the time available was limited. Study groups with classmates were somewhat helpful, but they often turned into social gatherings rather than focused study sessions. I needed a more reliable and structured form of support.
Discovering DatabaseHomeworkHelp.com
One evening, while frantically searching for online resources to understand an especially tricky ER diagram assignment, I stumbled upon DatabaseHomeworkHelp.com. The website promised expert help on a wide range of database topics, from basic queries to advanced database design and implementation. Skeptical but hopeful, I decided to give it a try. It turned out to be one of the best decisions I’ve made in my academic career.
First Impressions
The first thing that struck me about DatabaseHomeworkHelp.com was the user-friendly interface. The website was easy to navigate, and I quickly found the section where I could submit my assignment. The process was straightforward: I filled out a form detailing my assignment requirements, attached the relevant files, and specified the deadline.
Within a few hours, I received a response from one of their database experts. The communication was professional and reassuring. They asked a few clarifying questions to ensure they fully understood my needs, which gave me confidence that I was in good hands.
The Quality of Help
What impressed me the most was the quality of the assistance I received. The expert assigned to my task not only completed the assignment perfectly but also provided a detailed explanation of the solutions. This was incredibly helpful because it allowed me to understand the concepts rather than just submitting the work.
For example, in one of my assignments, I had to design a complex database schema. The expert not only provided a well-structured schema but also explained the reasoning behind each table and relationship. This level of detail helped me grasp the fundamental principles of database design, something I had been struggling with for weeks.
Learning and Improvement
With each assignment I submitted, I noticed a significant improvement in my understanding of database concepts. The experts at DatabaseHomeworkHelp.com were not just solving problems for me; they were teaching me how to solve them myself. They broke down complex topics into manageable parts and provided clear, concise explanations.
I particularly appreciated their help with SQL queries. Writing efficient and effective SQL queries was one of the areas I found most challenging. The expert guidance I received helped me understand how to approach query writing logically. They showed me how to optimize queries for better performance and how to avoid common pitfalls.
Timely Delivery
Another aspect that stood out was their commitment to deadlines. As a student, timely submission of assignments is crucial. DatabaseHomeworkHelp.com always delivered my assignments well before the deadline, giving me ample time to review the work and ask any follow-up questions. This reliability was a significant relief, especially during times when I had multiple assignments due simultaneously.
Customer Support
The customer support team at DatabaseHomeworkHelp.com deserves a special mention. They were available 24/7, and I never had to wait long for a response. Whether I had a question about the pricing, needed to clarify the assignment details, or required an update on the progress, the support team was always there to assist me promptly and courteously.
Affordable and Worth Every Penny
As a student, budget is always a concern. I was worried that professional homework help would be prohibitively expensive. However, I found the pricing at DatabaseHomeworkHelp.com to be reasonable and affordable. They offer different pricing plans based on the complexity and urgency of the assignment, making it accessible for students with varying budgets.
Moreover, considering the quality of help I received and the improvement in my grades, I can confidently say that their service is worth every penny. The value I got from their expert assistance far outweighed the cost.
A Lasting Impact
Thanks to DatabaseHomeworkHelp.com, my grades in the database course improved significantly. But beyond the grades, the most valuable takeaway has been the knowledge and confidence I gained. I now approach database assignments with a clearer understanding and a more structured method. This confidence has also positively impacted other areas of my studies, as I am less stressed and more organized.
Final Thoughts
If you're a student struggling with database management assignments, I highly recommend Database Homework Help from DatabaseHomeworkHelp.com. Their expert guidance, timely delivery, and excellent customer support can make a significant difference in your academic journey. They don’t just provide answers; they help you understand the material, which is crucial for long-term success.
In conclusion, my experience with DatabaseHomeworkHelp.com has been overwhelmingly positive. The support I received has not only helped me improve my grades but also enhanced my overall understanding of database concepts. I am grateful for their assistance and will undoubtedly continue to use their services as I progress through my computer science degree.

7 notes
·
View notes
Text
How to Transition from Biotechnology to Bioinformatics: A Step-by-Step Guide

Biotechnology and bioinformatics are closely linked fields, but shifting from a wet lab environment to a computational approach requires strategic planning. Whether you are a student or a professional looking to make the transition, this guide will provide a step-by-step roadmap to help you navigate the shift from biotechnology to bioinformatics.
Why Transition from Biotechnology to Bioinformatics?
Bioinformatics is revolutionizing life sciences by integrating biological data with computational tools to uncover insights in genomics, proteomics, and drug discovery. The field offers diverse career opportunities in research, pharmaceuticals, healthcare, and AI-driven biological data analysis.
If you are skilled in laboratory techniques but wish to expand your expertise into data-driven biological research, bioinformatics is a rewarding career choice.
Step-by-Step Guide to Transition from Biotechnology to Bioinformatics
Step 1: Understand the Basics of Bioinformatics
Before making the switch, it’s crucial to gain a foundational understanding of bioinformatics. Here are key areas to explore:
Biological Databases – Learn about major databases like GenBank, UniProt, and Ensembl.
Genomics and Proteomics – Understand how computational methods analyze genes and proteins.
Sequence Analysis – Familiarize yourself with tools like BLAST, Clustal Omega, and FASTA.
🔹 Recommended Resources:
Online courses on Coursera, edX, or Khan Academy
Books like Bioinformatics for Dummies or Understanding Bioinformatics
Websites like NCBI, EMBL-EBI, and Expasy
Step 2: Develop Computational and Programming Skills
Bioinformatics heavily relies on coding and data analysis. You should start learning:
Python – Widely used in bioinformatics for data manipulation and analysis.
R – Great for statistical computing and visualization in genomics.
Linux/Unix – Basic command-line skills are essential for working with large datasets.
SQL – Useful for querying biological databases.
🔹 Recommended Online Courses:
Python for Bioinformatics (Udemy, DataCamp)
R for Genomics (HarvardX)
Linux Command Line Basics (Codecademy)
Step 3: Learn Bioinformatics Tools and Software
To become proficient in bioinformatics, you should practice using industry-standard tools:
Bioconductor – R-based tool for genomic data analysis.
Biopython – A powerful Python library for handling biological data.
GROMACS – Molecular dynamics simulation tool.
Rosetta – Protein modeling software.
🔹 How to Learn?
Join open-source projects on GitHub
Take part in hackathons or bioinformatics challenges on Kaggle
Explore free platforms like Galaxy Project for hands-on experience
Step 4: Work on Bioinformatics Projects
Practical experience is key. Start working on small projects such as:
✅ Analyzing gene sequences from NCBI databases ✅ Predicting protein structures using AlphaFold ✅ Visualizing genomic variations using R and Python
You can find datasets on:
NCBI GEO
1000 Genomes Project
TCGA (The Cancer Genome Atlas)
Create a GitHub portfolio to showcase your bioinformatics projects, as employers value practical work over theoretical knowledge.
Step 5: Gain Hands-on Experience with Internships
Many organizations and research institutes offer bioinformatics internships. Check opportunities at:
NCBI, EMBL-EBI, NIH (government research institutes)
Biotech and pharma companies (Roche, Pfizer, Illumina)
Academic research labs (Look for university-funded projects)
💡 Pro Tip: Join online bioinformatics communities like Biostars, Reddit r/bioinformatics, and SEQanswers to network and find opportunities.
Step 6: Earn a Certification or Higher Education
If you want to strengthen your credentials, consider:
🎓 Bioinformatics Certifications:
Coursera – Genomic Data Science (Johns Hopkins University)
edX – Bioinformatics MicroMasters (UMGC)
EMBO – Bioinformatics training courses
🎓 Master’s in Bioinformatics (optional but beneficial)
Top universities include Harvard, Stanford, ETH Zurich, University of Toronto
Step 7: Apply for Bioinformatics Jobs
Once you have gained enough skills and experience, start applying for bioinformatics roles such as:
Bioinformatics Analyst
Computational Biologist
Genomics Data Scientist
Machine Learning Scientist (Biotech)
💡 Where to Find Jobs?
LinkedIn, Indeed, Glassdoor
Biotech job boards (BioSpace, Science Careers)
Company career pages (Illumina, Thermo Fisher)
Final Thoughts
Transitioning from biotechnology to bioinformatics requires effort, but with the right skills and dedication, it is entirely achievable. Start with fundamental knowledge, build computational skills, and work on projects to gain practical experience.
Are you ready to make the switch? 🚀 Start today by exploring free online courses and practicing with real-world datasets!
#bioinformatics#biopractify#biotechcareers#biotechnology#biotech#aiinbiotech#machinelearning#bioinformaticstools#datascience#genomics#Biotechnology
4 notes
·
View notes
Text
Creator sleeps well for someone as short as he. The creation stands tall and threathening outside the premises in the meanwhile for the full hours that he sleeps in. It gathers data, in the meantime. It learns about the server, and brand new revelations since its deactivation all those years ago. Fresh data, for a barely rusted bot.
It remembers Creator, when Creator worked in the white building of the Federation. He was freshly eighteen, landed a lucky job as an inventor after leaving his friend FitMC in a chaos of a server. His words, directly, and apart of the many many ramblings that Creator told it as he worked on it. The creation kept it all.
Well, for one, because it was needed. The storing of its eyes, ears, and mouth were vital to its purpose as a machine. It's an ever-learning database after all. The second is because it always ..."felt" right to keep them. It's Creator, and everything about him.
Shouldn't it store everything he says?
The four legged machine stands stationary outside the factory, arms close to its body as it sifts through all public information available to it. It collects online data, files the Federation hadn't properly closed, everything on Creator's account and computers strewn around his factory. It learns of names, players, locations, thoughts, and happenings. The creation stores this all in its systems for safe keeping.
It learns more about the shells, funnily enough. More than it needed to. It found names, history, and accounts. It pinpoints their location by the proper x, y, and z coordinates through their posted thoughts. A river, a camp, tents, and dozens of more... shells. Creation takes note, and uses more of its ability to access the console log.
/locate SunnySideUp
/locate Pepito
/locate Empanada
The sun rises as the moth inspired machine completes its data storage. It now has eyes and ears over every single active player on the server. Useful, for it rather than Creator. Creation debates staying for a little while longer, for Creator to wake up as well and finally, finally, greet it again.
Hello old friend, she'd say.
But it ultimately doesn't. Creator shouldn't know, what if he doesn't remember? What if he forgot? What if her Creation was never supposed to even be here? Creation doesn't bother finding out the true answer.
Its wings spread, fluttering like a helicopter blade, and it lifts off.
It could tell Creator needs help. Her health status was in poor condition. No sleep, low hunger, and since it checked, on four hearts. Creation treated him as best it could in the night avoiding detection. Creator looked worse, than he used to look when he was younger and overworked.
Creation could always pinpoint this decline on the shells. They did, after all, cause this to happen as far as it could tell. Journal entries that were left unread by anybody other than Creator were left on his desk. About how he was losing his mind, his nightmares, his dreams, and everything else he was able to jot down. No sign of his work, his most prized and impressive machinery, his Creation, however. That's alright.
But the shells, they were everywhere.
No, they were everything, to Creator.
They were on every page, every search history query, every account, and every other piece of data Creator got her hands on. It was impressed, of how rich this database was on these three shells alone. These... children. So clearly, they were important to Creator. So much, that her health declined without them.
So the most logical thing right now is to classify them as threats, right? They had caused Creator to nearly perish and add to the counter of player deaths, right?
Well, perhaps maybe not yet. Not until Creation can discern whether this was malicious intent. They are... young, after all. Small, and little. Usually not even a threat. But they're still important to find nonetheless. Regardless of their actions to its precious Creator.
Thin metal legs hit a branch of a tree, clamps acting as claws and firmly stabilizing itself on the wood. It creaks, crouching as a perched moth, with eyes narrowing to perform an area scan. Tents, about thirty blocks away, with small figures gathered around. Shells. And more than the three it had learned about. It makes quick work of connecting dots, names and faces to what's available on the server-wide web. More shells to look out for, more to study.
It's not here for any of those yet. It locks onto ones it finds on its extensive and Creator written database. The creation observes, it records audio and visuals, it learns. It watches over them, like a protective hawk.
Somehow, through its Creator, it finds an urge to allow them to be within its protection too. They are, without a doubt, incredibly important to him. It'd fail as his creation to not even consider those close to her. It could be scrapped, for this disobdience. It wouldn't mind, it considers.
Creation ceases all thoughts, instead choosing to focus on protecting this tiny civilation, from a distance. It's a guard machine, an emergency, not a person.
It needs to do as it's instructed.
2 notes
·
View notes
Note
Good luck on your source-finding journey friend! I am so interested in the process of tracking down sources and documents, but I've never done it before. Can you explain your process or do you have any tips?
Hi anon! Thanks for the ask. This is not a research guide, just some pointers I've found useful (as someone trained in other forms of academic research who learned how to work with archives).
First things first – forget google. Google scholar is decent for tracking down secondary academic sources (though hardly comprehensive), but with a few notable exceptions, archive databases that hold primary source materials are not indexed on normal search engines. Instead, you need to spend some time finding the repositories where your sought-after documents are likely to be, and then running your searches inside those.
The one thing google is useful for is to see if someone has already gone to the trouble of formally publishing the documents you're looking for. You'll want to search for things like "papers of...", "correspondence of...", or "writings of...". If you get a result, see if you can find that book on google books, archive.org, or at your local library (definitely don't check on libgen, because downloading a free book would be bad and awful and terrible of you 🤫).
These collected editions are not always reliable (especially older ones, since there was a lot of gratuitous editing going on). So, to be rigorous, you still want to see if you can find the actual, original source.
The easiest starting point for tracking those down is to find a secondary source that has already done most of the work for you. A reliable book or academic article will cite its primary sources, which should include which archive or collection the author found the document in.
If you are immeasurably lucky, you will find that respoitory online, and it will have a fully-digitised collection their holdings, and a reliable, searchable index based on keywords and transcripts. In that case, just type in your search term and enjoy.
(Note: the search functionality on these sites is often very wonky. Always try several versions of your search term, and play around with the filters and boolean operators.)
But those sites are rare. If you're less (but still a little bit) lucky, you'll find an academic institution or research archive that has at least published a document called a finding aid. There should be one for each grouping of documents in their holdings (for example for one historical figure's papers, or for a specific bequest) which gives a summary of the contents and is used for on-site tracking of the physical items (these will have call or accession numbers, location of the documents, etc.). Finding aids vary immensely in quality and level of detail ("miscellaneous other papers" my behated).
If you do indeed find a record for something you want to look at (and it hasn't been digitised), you need to figure out the process for requesting the document. This varies hugely depending on the institution (with differing lead times, querying methods, fees, limitations, and ensuing publication/reproduction rights) and is virtually always explained somewhere on their website. Mostly, they'll ask you to complete a form, or to send an email following a template. Don't expect a quick reply, and don't expect digital copies to be free.
Of course, this all presumes that the instituton that holds your materials 1) has a website and 2) has actually put useful things on it. Sometimes, you just need to enquire. I followed up on a footnote I saw in a hundred-year-old book that gave the location of some letters, found the local town library that was mentioned and emailed them about it. (Yes, they had them, and the librarian I corresponded with was simply delightful and very eager to help.)
Be courteous and clear when you email these folks. They will almost always want to know your name, your contact details, a clear description of what you are looking for (the more detail the better), a summary of your research project, and whether you intend to publish the documents you are requesting – so save a few back-and-forth emails by providing that information upfront. They are very happy to answer requests from independent or hobby researchers, so don't let that hold you back.
The least helpful of all, in my experience, are holders of private collections. They simply don't have any incentive to take time out of their day to help you, and usually aren't trained librarians or archivists so they don't know what they have, or where it is, or how to give you access. (I tear up sometimes when I think of all the documents that are lying in some manor house attic, because someone forgot they were there or thought no one would be interested.) Sometimes they will respond (eventually) to an email query; often it's just a black hole.
I hope that helps! In all frankness, much of this is dull, repetitive work that all-too-frequently leads to dead ends (but it's so good when you succeed). Persistence and patience are key.
#feel free to ask follow-up questions#especially something more specific because this is a very broad topic#and i encourage the skilled research folks on here to add their own tips#historical research
7 notes
·
View notes
Text
SQL GitHub Repositories
I’ve recently been looking up more SQL resources and found some repositories on GitHub that are helpful with learning SQL, so I thought I’d share some here!
Guides:
s-shemee SQL 101: A beginner’s guide to SQL database programming! It offers tutorials, exercises, and resources to help practice SQL
nightFuryman SQL in 30 Days: The fundamentals of SQL with information on how to set up a SQL database from scratch as well as basic SQL commands
Projects:
iweld SQL Dictionary Challenge: A SQL project inspired by a comment on this reddit thread https://www.reddit.com/r/SQL/comments/g4ct1l/what_are_some_good_resources_to_practice_sql/. This project consists of creating a single file with a column of randomly selected words from the dictionary. For this column, you can answer the various questions listed in the repository through SQL queries, or develop your own questions to answer as well.
DevMountain SQL 1 Afternoon: A SQL project where you practice inserting querying data using SQL. This project consists of creating various tables and querying data through this online tool created by DevMountain, found at this link https://postgres.devmountain.com/.
DevMountain SQL 2 Afternoon: The second part of DevMountain’s SQL project. This project involves intermediate queries such as “practice joins, nested queries, updating rows, group by, distinct, and foreign key”.
36 notes
·
View notes
Note
Hello, I’ve been following your blog because it’s interesting to hear about your journey for coding and the absolute joy that I see as you talk about it. S o I wish you the best! And i’m curious, currently I’m training to be a health administrator. Is there any starting coding programs or any subjects in coding or programming that I can pick up?
Hiya!
First of all, thanks so much for reaching out and following along on my journey (4 years going strong LET'S GO!). It truly means a lot to hear that you find it interesting enough - that's exactly the feeling I hope to convey!
Second, courses in coding/programming in regards to Health Admin; from the top of my head, I would presume that data would be involved, so any SQL courses online would help! SQL is a fundamental programming language for querying and manipulating data stored in relational databases. Getting good at it could be a plus! (Always looks nice on a CV/Resume anyways~).
Python could also be good for data analysis. Also, look into Medical Coding and see if that's something you want to go into later - it's like if you merged healthcare with programming! I don't know courses from the top of my head but you can find courses on Udemy, Coursea, or even for free YouTube (more for SQL and Python) or buy a course that gives you a certificate at the end to add to your resume or LinkedIn in the end!
Good luck! 🌷
11 notes
·
View notes
Text
Questions About Publishing
There is a LOT of misinformation and confusion in online writing forums about getting published.
In general, if you are asking a question about publishing before finishing your manuscript, you are getting ahead of yourself and overthinking something. None of this stuff matters in the early stages. Don’t fuss around asking strangers on the internet about random aspects of the publishing world. Spend that time writing. Worry about how publishing works once you’re done.
Even worrying about “if I write XYZ, can that get published?” - if you’re not a working genre fiction writer who is writing to market, don’t worry about it. Read what’s being published in that genre, and spend your energy on your manuscript.
Note that all this advice is for publishing novels - for info on short stories and poems, see the bottom of this post.
When it comes to publishing a novel, in short, there are two ways to do it. The first one, which is what most people think of when they say “getting published,” is traditional publishing. The way this works is:
Steps To Traditional Publishing
Step One: Author completes a manuscript. The length of this manuscript will be dictated by the realities of what it takes to tell your story, and what the market in general is looking for (basic info here).
Step Two: Author polishes and edits manuscript. This could include developmental editing, which looks at your plot, structure, overall story, etc. and copy editing, which checks for grammar and spelling mistakes.
It is possible to hire services for this, but it’s not generally required. If you can have a trusted friend go over it or find a fellow writer to swap this sort of work with, that’s also fine. Do not believe that in order to have a shot at getting an agent, you need to spend hundreds of dollars on a third party editing service.
Step Three: Author develops a query package. You will need to write a query letter for your book, which explains what your book is about, what genre it’s in, and what currently popular books are similar to it. Some agents also want to see things like a blurb (a teaser/hook for your book) or synopsis (detailed summary of the entire plot).
Query letters are hard! But they are easier to do once your book is done, so don’t fuss about it until you’re done writing. When it’s time, here are resources for writing your query:
Query Shark
How to write an awesome query letter
NY Book Editors query letter advice
Step Four: Author queries agents with their manuscript. There are directories that will tell you what agents are accepting queries, and in what genres, and what type of books they’re looking for. There will be information about what the agent wants to see (query letter, length of synopsis, first few pages), and how they want it to be formatted and sent.
Find agents that seem like a good fit, and take the time to tailor a query package based on what they want to see. Use a spreadsheet to keep track of who you have sent queries to and when. Here are some good sites to find agents:
Manuscript Wish List
Publishers Marketplace
Agent Query
Poets & Writers Agent Database
Step Five: Patience. It takes a while to hear back from agents. Some may turn you down outright, while others might request a full manuscript to read.
If you get an offer of representation from an agent, you do not need to accept it immediately. Look over the contract they would have you sign, and make sure you understand and accept its terms. Chat with them about your career goals and ask lots of questions. Ask if you can speak with other authors they represent. Let any other agents who currently have your query package know right away that you have gotten an offer, and give them time to make a competing offer.
Step Six: Having an agent. Once you have an agent, they will help you deal with everything from there on out. They will pitch your book to publishers and help represent you when dealing with publishing contracts. Marketing and publicity, launch and debut, cover art, adaptation rights, etc. You will not need to ask people on the internet for advice on this or worry about doing it yourself.
You may not get an agent! If everyone you send a query to turns you down, you might need to revise your query package or look for different agents. It’s a tough process - but it’s very doable once you have a solid, polished, finished manuscript. And there are some publishers that will accept un-agented submissions - this is called the “slush pile,” and it’s an even rougher go than getting an agent.
Note that at no point during this traditional publishing journey should you need to shell out large amounts of cash. Money flows to the author, never away from the author. You do not need to worry about paying an artist to make you a cover, or paying for things like social media and marketing.
The other form of publishing is self publishing, sometimes called indie publishing. In this format, you publish your book yourself using a platform like Amazon Kindle. You are then responsible for marketing, publicity, cover art, editing, formatting, etc. There are some people who make a lot of money doing this, but they spend a lot of time putting out frequent, consistent books in very in-demand genres. Self publishing a single novel, especially one in a less commercial genre, will likely not lead to much attention or money.
Steps to Self Publishing
Step One: Complete your manuscript.
Step Two: Edit and polish your manuscript. Since you are not going to have access to the resources of a large publishing company, you may wish to pay for editing services. However, keep track of these costs and be realistic about your choices.
Step Three: Research the market. Look at similar books on Amazon, Goodreads, BookBub, and bookish social media. Notice what types of tags and keywords people are using. Understand how people are presenting and marketing similar books.
Step Four: Develop assets. You will need an ebook cover and a print option cover if you want to make that available. You will also need to format your book for print and e-readers. You will also want to have an author website, possibly a newsletter, and social media presence. Some of this may cost money, especially if you want to hire an artist for your cover or use powerful social media tools. This is not the same as paying a publisher to publish your book.
Step Five: Build pre-launch buzz for your book. Connect with similar authors and readers on social media. Consider recruiting ARC readers and reviewers using websites like BookSprout or Book Sirens. Again, some of this might cost money for tools or services. Keep track of your costs and don’t go overboard.
Step Six: Launch your book. Many authors use the Kindle platform for this. There are pros and cons to their Kindle Unlimited program, so do your research. Use well researched keywords, tags, and strong promotional copy. Make sure it is added to Goodreads and BookBub. Consider ad campaigns on social media.
Step Seven: Repeat, repeat, repeat. Making money as a self published author requires consistent output. Write and publish more books. Keep up your social media, blog, or newsletter. Keep an eye on trends in your genre. Participate in online communities and avenues to getting more eyeballs, like BookFunnel promotions.
Resources on self publishing:
Jane Friedman's guide to self publishing
Self publishing vs traditional publishing
How do you successfully self publish?
Dabble Writer self publishing guide
Paying For Publishing
You may see references to “vanity presses” or “hybrid” publishing. THESE ARE A SCAM. Basically, these are companies that pretend to be publishers, and say that they are willing to publish your book, but require you to pay them for things like printing costs, marketing, editing, etc. This is not a good way to get your book published, because you will spend more money than your book will make.
There is no prestige in “getting published” this way, because the publisher isn’t taking the highest quality books, but just whoever can pay them. And they will not be invested in your success, because you have already paid them. It is unlikely that they will get your book into bookstores or have the ability to help you rank high in Amazon and other searches.
If a publisher reaches out to you rather than you submitting to them, they are a scam. If a publisher asks you to front the costs for putting your book out, they are a scam. And if you do “publish” a book with one of these places, that will kill your ability to get it published elsewhere, because most legitimate publishers require first rights.
Beware, also, of self-styled gurus that will tell you how to make tons of money in self publishing if you only buy their course or sign up for their services on how to run the perfect ad campaign or become a seven figure indie author.
Always check Writer Beware before getting involved with any sort of publishing scheme.
4 notes
·
View notes
Text
MS Office - Introduction
Microsoft Office is a software which was developed by Microsoft in 1988. This Office suite comprises various applications which form the core of computer usage in today’s world.
MS Office Applications & its Functions
Currently, MS Office 2016 version is being used across the world and all its applications are widely used for personal and professional purposes.
Discussed below are the applications of Microsoft Office along with each of their functions.
1. MS Word
First released on October 25, 1983
Extension for Doc files is “.doc”
It is useful in creating text documents
Templates can be created for Professional use with the help of MS Word
Work Art, colours, images, animations can be added along with the text in the same file which is downloadable in the form of a document
Authors can use for writing/ editing their work
To read in detail about Microsoft Word, its features, uses and to get some sample questions based on this program of Office suite, visit the linked article.
2. MS Excel
Majorly used for making spreadsheets
A spreadsheet consists of grids in the form of rows and columns which is easy to manage and can be used as a replacement for paper
It is a data processing application
Large data can easily be managed and saved in tabular format using MS Excel
Calculations can be done based on the large amount of data entered into the cells of a spreadsheet within seconds
File extension, when saved in the computer, is “.xls”
Also, visit the Microsoft Excel page to get more information regarding this spreadsheet software and its components.
3. MS PowerPoint
It was released on April 20, 1987
Used to create audiovisual presentations
Each presentation is made up of various slides displaying data/ information
Each slide may contain audio, video, graphics, text, bullet numbering, tables etc.
The extension for PowerPoint presentations is “.ppt”
Used majorly for professional usage
Using PowerPoint, presentations can be made more interactive
In terms of Graphical user interface, using MS PowerPoint, interesting and appealing presentation and documents can be created. To read more about its features and usage, candidates can visit the linked article.
4. MS Access
It was released on November 13, 1992
It is Database Management Software (DBMS)
Table, queries, forms and reports can be created on MS Access
Import and export of data into other formats can be done
The file extension is “.accdb”
5. MS Outlook
It was released on January 16, 1997
It is a personal information management system
It can be used both as a single-user application or multi-user software
Its functions also include task managing, calendaring, contact managing, journal logging and web browsing
It is the email client of the Office Suite
The file extension for an Outlook file is “.pst”
6. MS OneNote
It was released on November 19, 2003
It is a note-taking application
When introduced, it was a part of the Office suite only. Later, the developers made it free, standalone and easily available at play store for android devices
The notes may include images, text, tables, etc.
The extension for OneNote files is “.one”
It can be used both online and offline and is a multi-user application.
3 notes
·
View notes
Text
The Data Migration Odyssey: A Journey Across Platforms
As a database engineer, I thought I'd seen it all—until our company decided to migrate our entire database system to a new platform. What followed was an epic adventure filled with unexpected challenges, learning experiences, and a dash of heroism.
It all started on a typical Monday morning when my boss, the same stern woman with a flair for the dramatic, called me into her office. "Rookie," she began (despite my years of experience, the nickname had stuck), "we're moving to a new database platform. I need you to lead the migration."
I blinked. Migrating a database wasn't just about copying data from one place to another; it was like moving an entire city across the ocean. But I was ready for the challenge.
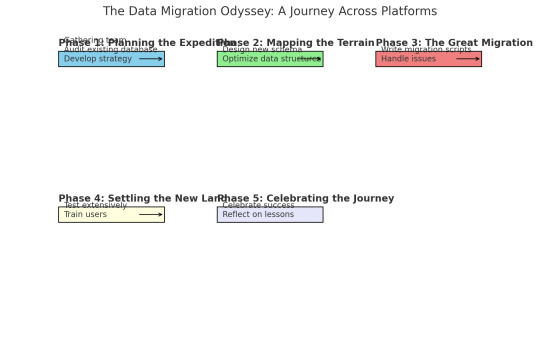
Phase 1: Planning the Expedition
First, I gathered my team and we started planning. We needed to understand the differences between the old and new systems, identify potential pitfalls, and develop a detailed migration strategy. It was like preparing for an expedition into uncharted territory.
We started by conducting a thorough audit of our existing database. This involved cataloging all tables, relationships, stored procedures, and triggers. We also reviewed performance metrics to identify any existing bottlenecks that could be addressed during the migration.
Phase 2: Mapping the Terrain
Next, we designed the new database design schema using schema builder online from dynobird. This was more than a simple translation; we took the opportunity to optimize our data structures and improve performance. It was like drafting a new map for our city, making sure every street and building was perfectly placed.
For example, our old database had a massive "orders" table that was a frequent source of slow queries. In the new schema, we split this table into more manageable segments, each optimized for specific types of queries.
Phase 3: The Great Migration
With our map in hand, it was time to start the migration. We wrote scripts to transfer data in batches, ensuring that we could monitor progress and handle any issues that arose. This step felt like loading up our ships and setting sail.
Of course, no epic journey is without its storms. We encountered data inconsistencies, unexpected compatibility issues, and performance hiccups. One particularly memorable moment was when we discovered a legacy system that had been quietly duplicating records for years. Fixing that felt like battling a sea monster, but we prevailed.
Phase 4: Settling the New Land
Once the data was successfully transferred, we focused on testing. We ran extensive queries, stress tests, and performance benchmarks to ensure everything was running smoothly. This was our version of exploring the new land and making sure it was fit for habitation.
We also trained our users on the new system, helping them adapt to the changes and take full advantage of the new features. Seeing their excitement and relief was like watching settlers build their new homes.
Phase 5: Celebrating the Journey
After weeks of hard work, the migration was complete. The new database was faster, more reliable, and easier to maintain. My boss, who had been closely following our progress, finally cracked a smile. "Excellent job, rookie," she said. "You've done it again."
To celebrate, she took the team out for a well-deserved dinner. As we clinked our glasses, I felt a deep sense of accomplishment. We had navigated a complex migration, overcome countless challenges, and emerged victorious.
Lessons Learned
Looking back, I realized that successful data migration requires careful planning, a deep understanding of both the old and new systems, and a willingness to tackle unexpected challenges head-on. It's a journey that tests your skills and resilience, but the rewards are well worth it.
So, if you ever find yourself leading a database migration, remember: plan meticulously, adapt to the challenges, and trust in your team's expertise. And don't forget to celebrate your successes along the way. You've earned it!
6 notes
·
View notes
Note
❛ to be fair i only killed those at the gate. ❜ [Kyumin & Jeremy]
. 𓇬 𝖒𝖊𝖒𝖊𝖘 .

jeremy didn't often venture out when the league staged events like this one. more often than not, it was the figments of his imagination that took his place. yet today felt different. he had warned the younger about the importance of maintaining a low profile as they infiltrated the government building. their mission: to extract files too sensitive to be uploaded to the online database.
however, when kyu revealed what he'd done, jeremy couldn't help but feel a twinge of relief that his counterpart's quirk wasn't always so conspicuous. true, a pile of ash would be the only evidence of their presence, but as long as they remained undetected, jeremy assumed they were in the clear.
❛⠀what happened to keeping a low profile?⠀❜ he queried, his tone carrying a subtle warning as he gestured casually towards the file room. ❛⠀i'll keep watch. you know what to do.⠀❜ with that, he handed ash the device programmed by their counterpart to bypass the passcode.
2 notes
·
View notes
Text
Database Dynamics: Unraveling the Secrets to Affordable and Trustworthy Homework Help

In the intricate world of academia, students often find themselves grappling with the complexities of database-related assignments. The demand for proficient individuals in this field has led to an increased need for quality education and support. As the phrase "do my UML homework" echoes in the minds of students, seeking reliable assistance becomes paramount. This blog aims to shed light on the dynamics of finding affordable and trustworthy database homework help, ensuring that students can navigate the vast landscape of online resources with confidence.
Understanding the Need for Database Homework Help:
Before delving into the secrets of finding the right assistance, it's crucial to understand why students seek help with their UML homework and other database-related tasks. The world of databases is multifaceted, encompassing various concepts such as data modeling, SQL queries, normalization, and UML diagrams. As coursework becomes more intricate, students often require guidance to bridge the gap between theoretical knowledge and practical application.
The Keyword Dilemma: "Do My UML Homework":
The quest for the right database homework help begins with the articulation of the student's needs. The keyword "do my UML homework" encapsulates the essence of the assistance required. It signifies a plea for support in understanding and implementing Unified Modeling Language (UML) concepts, a fundamental aspect of database design and development.
Secret #1: Thorough Research is Key:
Embarking on the journey to find reliable assistance involves meticulous research. Start by exploring online platforms that specialize in database-related subjects. Pay attention to websites that showcase their expertise in UML and other relevant areas. Read reviews and testimonials from previous clients to gauge the efficacy of the service.
Secret #2: Legitimacy Matters:
To unravel the secrets of affordable and trustworthy homework help, one must decipher the legitimacy of the service. Legitimate platforms provide comprehensive information about their operations, including the qualifications of their tutors, certifications, and affiliations. A transparent service is more likely to deliver on its promises.
Secret #3: Tutors' Qualifications Speak Volumes:
The heart of any database homework help service lies in the qualifications of its tutors. Look for platforms that showcase detailed profiles of their tutors, highlighting their academic and professional backgrounds. Tutors with a wealth of experience in UML and database concepts are better equipped to provide meaningful assistance.
Secret #4: Balancing Affordability and Quality:
Affordability is a critical factor for students seeking homework help. However, it's essential to strike a balance between cost and quality. Opt for services that offer competitive pricing without compromising on the standard of assistance. Some platforms may provide discounts or packages for regular users, ensuring cost-effectiveness.
Secret #5: Sample Work and Guarantees:
A reliable database homework help service often exhibits samples of its work. Analyzing these samples provides insight into the quality of assistance you can expect. Additionally, look for services that offer guarantees such as plagiarism-free work and on-time delivery, ensuring a stress-free experience for students.
Secret #6: 24/7 Support for Round-the-Clock Assistance:
In the dynamic realm of academia, the need for support can arise at any time. Choose a database homework help service that provides 24/7 customer support. A responsive support team ensures that queries can be addressed promptly, fostering a collaborative and efficient learning environment.
Conclusion:
As students navigate the labyrinth of database dynamics, the secrets to finding affordable and trustworthy homework help become invaluable. By conducting thorough research, ensuring legitimacy, evaluating tutors' qualifications, balancing affordability and quality, reviewing sample work, and securing reliable customer support, students can unlock the full potential of their educational journey.
So, the next time the phrase "do my UML homework" reverberates in your academic pursuits, armed with these secrets, you can confidently choose a database homework help service that aligns with your needs and propels you towards success in the fascinating world of databases.
3 notes
·
View notes